Building a Multi-Vendor Network Lab: EVE-NG Meets Containerlab.

How I built a 16-device, 4-vendor lab for network automation, and what broke along the way.
The Wall
I kept seeing the same questions in community spaces. Slack channels, Discord servers, Reddit threads, study groups: "How are you running multi-vendor labs at home?" "Can I run SR Linux next to Cisco CML images?" "What's the realistic way to test automation against something other than just IOS?"
The honest answer was messy. Most labs are still single-vendor or single-platform. People either run EVE-NG with a fleet of Cisco images, or they spin up Containerlab with FRR and SR Linux, but rarely both.
I realized my own lab had the same problem. It was comfortably Cisco-centric: six C8000V routers, three Cat9kv switches, all running modern IOS-XE with NETCONF and streaming telemetry. Great for testing Cisco-specific features. Terrible for challenging assumptions.
The moment that changed my thinking: I had written a parser that extracted OSPF neighbor state. It worked beautifully against my lab. Then I tried it against a customer environment that included Arista and Juniper devices. My hardcoded show ip ospf neighbor failed immediately. The syntax was close enough to be dangerous, different enough to break everything.
That failure taught me something. Production networks are not single-vendor. Labs should not be either.
So I set out to build something different: a lab that felt like production. Enterprise routers running full IOS-XE alongside containerized network operating systems. Multiple routing protocols crossing platform boundaries. A setup that would actively break automation assumptions before production ever got the chance.
The result: 16 devices, 4 vendors, 2 simulation platforms running side by side.
Why Two Platforms?
No single simulation platform does everything well.
Cisco IOS-XE images like the C8000V and Cat9kv require KVM or QEMU. These are full virtual machines, typically consuming 4-8 GB of RAM each and taking minutes to boot. They give you the real operating system with all its features: NETCONF, RESTCONF, Model-Driven Telemetry, the works. But they are heavy.
Open-source network operating systems like FRRouting and Nokia SR Linux are container-native. They spin up in seconds, consume a fraction of the resources, and can be orchestrated with standard container tooling. But they cannot replace the enterprise images when you need to test vendor-specific features.
This creates a natural split.
EVE-NG for Enterprise Images → Runs Cisco, Juniper, Palo Alto, Fortinet VMs. Provides topology designer, browser console access, integrated Wireshark captures. If you need real IOS-XE with working NETCONF, gNMI, and MDT, this is your option.
Containerlab for Container-Native NOS → Orchestrates container-based network operating systems using YAML topology definitions. Nokia SR Linux, FRRouting, SONiC, Arista cEOS—all available as container images. docker pull a network OS, wire it into a topology, have a working lab in under a minute.
I chose to run both. EVE-NG hosts the "enterprise core": six Cisco C8000V routers and three Cat9kv switches. Containerlab hosts the "edge and datacenter": FRRouting instances as BGP edge routers, a Nokia SR Linux spine switch, and Alpine Linux hosts as traffic endpoints.
Two worlds, one lab. The boundary between them turned out to be the most interesting part.
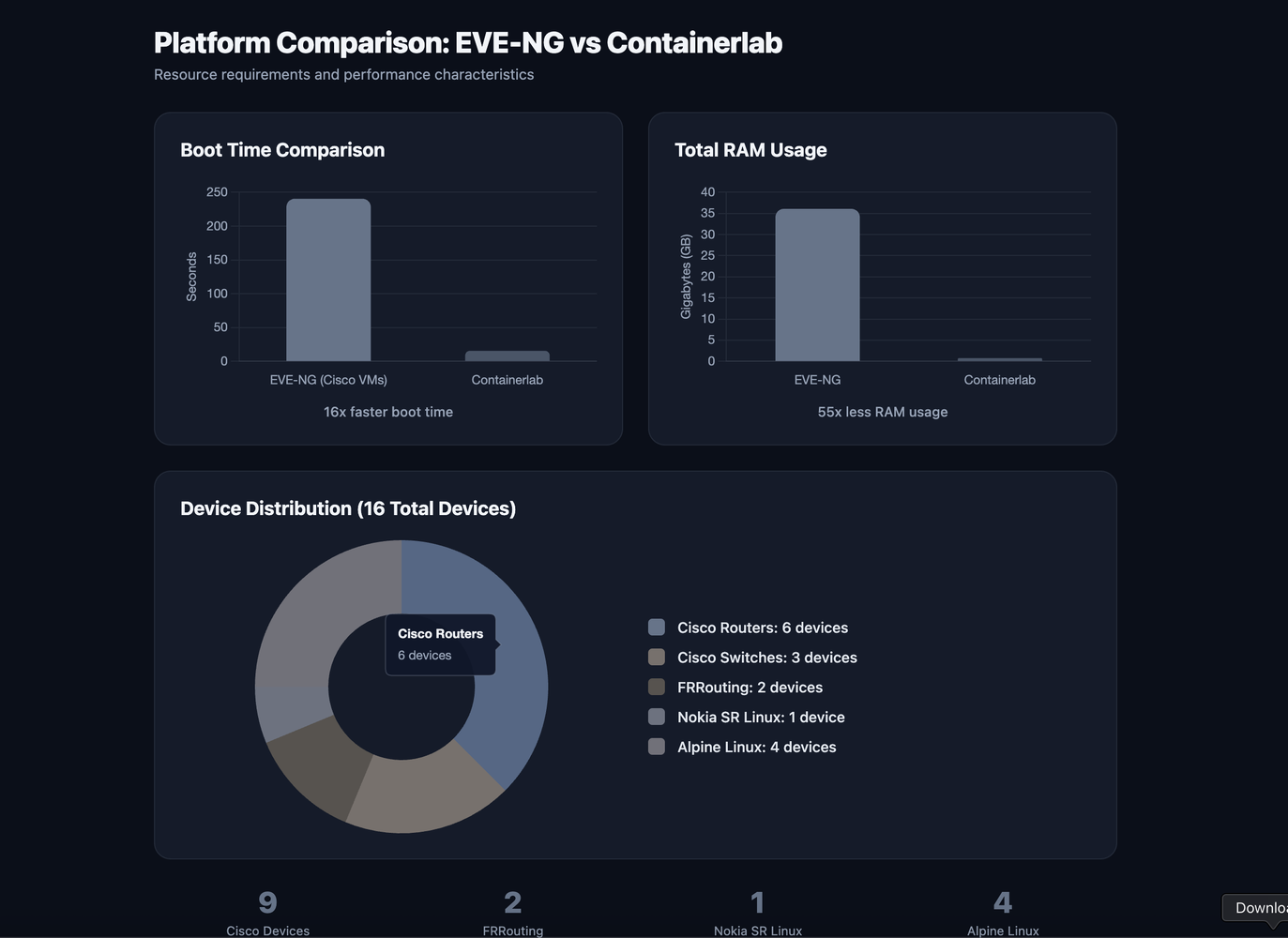
EVE-NG vs Containerlab: 16x faster boot, 55x less RAM. The trade-off is feature fidelity—Cisco VMs give you full IOS-XE, containers give you speed.
The Lab Topology
The full inventory:
EVE-NG (Cisco IOS-XE 17.13.1a)
R1, R2, R3, R4, R6, R7 → C8000V core routers
Switch-R1, Switch-R2, Switch-R4 → Cat9kv access switches
Containerlab
edge1, R9 → FRRouting BGP edge routers
spine1 → Nokia SR Linux datacenter spine
server1, server2 → Alpine Linux traffic endpoints
Why These Choices
Each selection was deliberate.
Cisco C8000V with IOS-XE 17.13: Mature NETCONF/YANG support. Model-Driven Telemetry with gRPC dial-out. RESTCONF for quick health checks. Older 16.x versions lack MDT dial-out entirely.
Cisco Cat9kv: Real switching OS, not limited IOSvL2. Spanning-tree works. VLANs behave correctly. QoS policies apply as expected.
FRRouting: Production-grade open-source routing. Cumulus, DENT, and SONiC all use FRR. The CLI looks Cisco-like but isn't Cisco. Commands are close enough to confuse you, different enough to break hardcoded parsers. That's exactly the point.
Nokia SR Linux: Completely different paradigm. gNMI-native from the ground up. If your code assumes show ip route works everywhere, SR Linux will break that assumption immediately.
Topology Design
The logical design mirrors enterprise patterns:
Hub-spoke DMVPN → R1 as hub, R2/R3/R4/R6/R7 as spokes. Realistic enterprise WAN pattern.
Multi-area OSPF → Area 0 across the core, Area 1 and Area 2 at branches. Route summarization, inter-area filtering, LSA propagation.
eBGP edge peering → R3 peers with edge1 via eBGP. This session crosses the platform boundary: Cisco VM in EVE-NG to FRR container in Containerlab. Getting this up was the hardest part.
EIGRP over DMVPN → The overlay routing protocol. Tests authentication, split-horizon, route advertisement across tunnels.
Out-of-band management → Every device in 10.255.255.0/24, separate from data plane. Mirrors production patterns, prevents lockouts.
Connecting the Platforms
The architecture looks straightforward on paper:
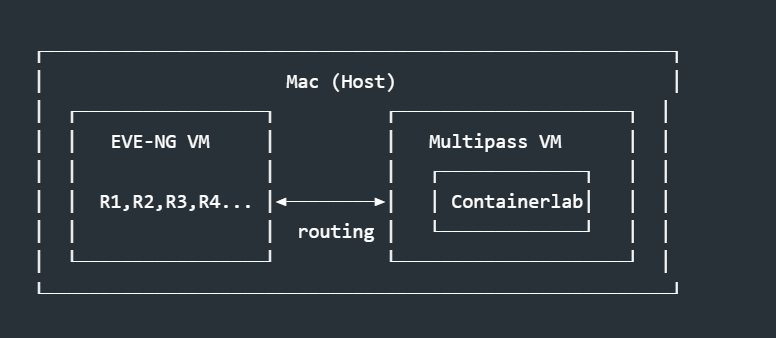
In practice, there's a bubble problem. EVE-NG devices live in one network segment. Containerlab devices live in another, inside a Docker bridge within the Multipass VM. Initially, these two worlds cannot see each other.
The Routing Challenge
EVE-NG devices are bridged to my Mac's network. Containerlab runs inside a Multipass VM, with containers on a Docker bridge network. From outside that VM, the container network is invisible.
For eBGP between R3 (EVE-NG) and edge1 (Containerlab), packets need to route correctly in both directions.
The Solution
Routes at multiple layers:
EVE-NG server needs a route to the Containerlab network
Mac needs IP forwarding enabled with appropriate routes
Containerlab topology needs an external interface reaching back to EVE-NG
Once routing is in place, R3 can ping edge1, TCP sessions establish, BGP comes up.
The Gotchas
eBGP Over Management Network: I initially tried a dedicated transit link with GRE tunnel. GRE protocol 47 doesn't traverse Docker's networking stack cleanly without significant iptables modifications.
The pragmatic solution: peer eBGP over management. R3 uses its management interface to reach edge1's Docker IP. Requires ebgp-multihop since peers aren't directly connected.
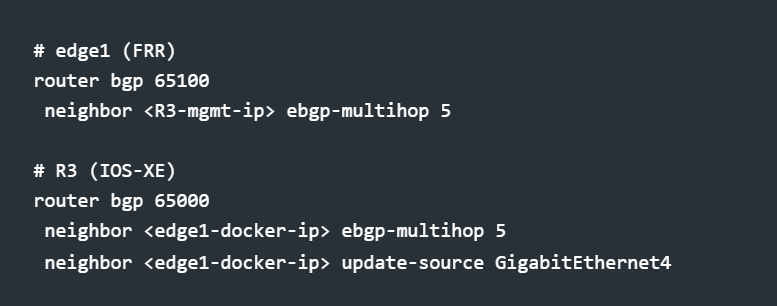
Is this how you'd design production? No. Management and control planes should be separate. But for a lab testing multi-vendor BGP behavior, the trade-off is acceptable.
Route Persistence: The static route on EVE-NG doesn't survive reboots. After a power cycle, R3 suddenly can't reach edge1. BGP shows Active instead of Established.
Fix: Add the static route to /etc/rc.local on the EVE-NG server so it persists across reboots.
Subtle integration issue at the platform boundary. Works perfectly in testing, breaks silently after maintenance.
The 2-hour debug: BGP stuck in Active state because EVE-NG couldn't reach the Containerlab network. One static route fixed it—but it disappears after every reboot.
Management Network Design
I allocated a dedicated /24 subnet as out-of-band management. Every device has a management interface here, separate from routing protocols.
The pattern encodes device type into the address. Routers in one range, switches in another, containers in a third. Predictable scheme means I know where a new device will land before I create it.
More importantly, management separation enables safe failure testing. I can simulate "data plane down, management up" scenarios. A failed config push doesn't lock me out.
Why These OS Versions Matter
Version selection is an automation decision, not just stability.
Cisco IOS-XE 17.13
Mature NETCONF/YANG → Complete, stable models. Structured configuration instead of parsing text.
Model-Driven Telemetry → gRPC dial-out streams interface stats every few seconds. No more polling SNMP every 5 minutes.
RESTCONF → Quick health checks without SSH overhead.
Older 16.x releases lack MDT dial-out entirely. Some YANG models incomplete. Version matters.
Nokia SR Linux
gNMI-native by design. No NETCONF translation layer. Completely different CLI that exposes every assumption your automation makes about syntax and data models.
FRRouting
Powers Cumulus, SONiC, and other production platforms. The vtysh CLI looks Cisco-like, which is both helpful and dangerous. show ip ospf neighbor works—but output format differs subtly. Column widths, headers, state representations. Any parser relying on exact string matching will fail.
The Version vs Feature Matrix
IOS-XE 16.x → Partial NETCONF, no gNMI, no MDT dial-out, limited RESTCONF
IOS-XE 17.x → Full NETCONF, gNMI, MDT dial-out, full RESTCONF
SR Linux → No NETCONF, native gNMI, JSON-RPC
FRR → CLI parsing required
If you want to avoid CLI parsing entirely, you need modern IOS-XE for Cisco or gNMI for SR Linux.
Lessons Learned:
Start Multi-Vendor from Day One
I started Cisco-only and retrofitted multi-vendor later. Mistake. Found show ip ospf neighbor hardcoded in a dozen places, each a silent failure waiting to happen.
If I rebuilt today, I'd include at least one non-Cisco device from the start.
Container-Native NOS Is the Future
SR Linux and FRR spin up in seconds. Cisco VMs take minutes and gigabytes of RAM. The industry is moving toward containerized network operating systems. SONiC adoption by hyperscalers. Vendors shipping container images.
In five years, most labs will be container-first, with VMs reserved for legacy vendor images.
Platform Boundaries Are Where Things Break
Every interesting failure was at a boundary. The eBGP session between EVE-NG and Containerlab. Routing between VM and container networks. Data model differences between Cisco YANG and SR Linux gNMI.
The eBGP session taught me more about routing fundamentals than months of single-platform work. When it fails between two Cisco routers, you check usual suspects. When it fails between a Cisco VM and an FRR container in a different hypervisor, you also consider Docker networking, bridge interfaces, IP forwarding, route persistence, NAT behavior.
If you're troubleshooting integration issues, start at the boundaries.
Management Separation Pays Off Immediately
Feels like extra work during setup. Pays off the first time a bad config push takes down a routing protocol but leaves management access intact.
Version Selection Is an Automation Decision
Choosing IOS-XE 17.13 over 16.x is the difference between streaming telemetry and SNMP polling. Don't just pick "latest." Pick the version with the programmability features you need.
Closing
What surprised me most: the platform boundary was harder than the multi-vendor CLI differences. I expected parsing and syntax to be the main challenges. They weren't. Getting packets to route between EVE-NG VMs and Containerlab containers took more troubleshooting than any CLI difference.
Integration problems live at boundaries. Between platforms, between vendors, between control planes. If something isn't working, check the boundaries first.
If you want to try this hybrid model, start small. Three Cisco VMs in EVE-NG and one FRR container in Containerlab. Get eBGP peering across that boundary. The moment the session comes up and routes start exchanging, you'll understand the architecture and the tradeoffs.
The multi-vendor, multi-platform approach forced me to write better code. Abstractions that actually abstract, not just wrappers around Cisco commands. Parsers that handle variance, not just the happy path. Health checks that query capabilities first rather than assuming every device speaks the same language.
If your lab only confirms what you already know, it's not doing its job. A good lab should break things. It should find the assumptions hiding in your automation before production does.
This one does exactly that.
Elliot Conner Network Automation Architect | CCNP Enterprise