Change Management Is Trust Engineering
How I Taught My Automation to Earn My Confidence
Every network engineer knows the moment. Your finger hovers over Enter. The change looks right. You've checked it twice. But somewhere in the back of your mind, a voice asks: What if I'm wrong?
That hesitation isn't weakness. It's wisdom. Networks are graphs, and graphs hide dependencies invisible from any single config file. The interface you're about to modify might carry OSPF adjacencies you forgot about, or serve as the only path for routes you didn't know existed. "I'll just paste this config" has ended careers. I built NetworkOps because I wanted to eliminate that fear, not by removing human judgment, but by giving humans better information before they commit to action.
The Shift
Traditional change management is a prayer disguised as a process: make the change, hope nothing breaks, scramble if it does. Modern change management inverts this. The system tells you what will happen before you commit. Now I describe intent. The system shows consequences.
How Impact Analysis Actually Works
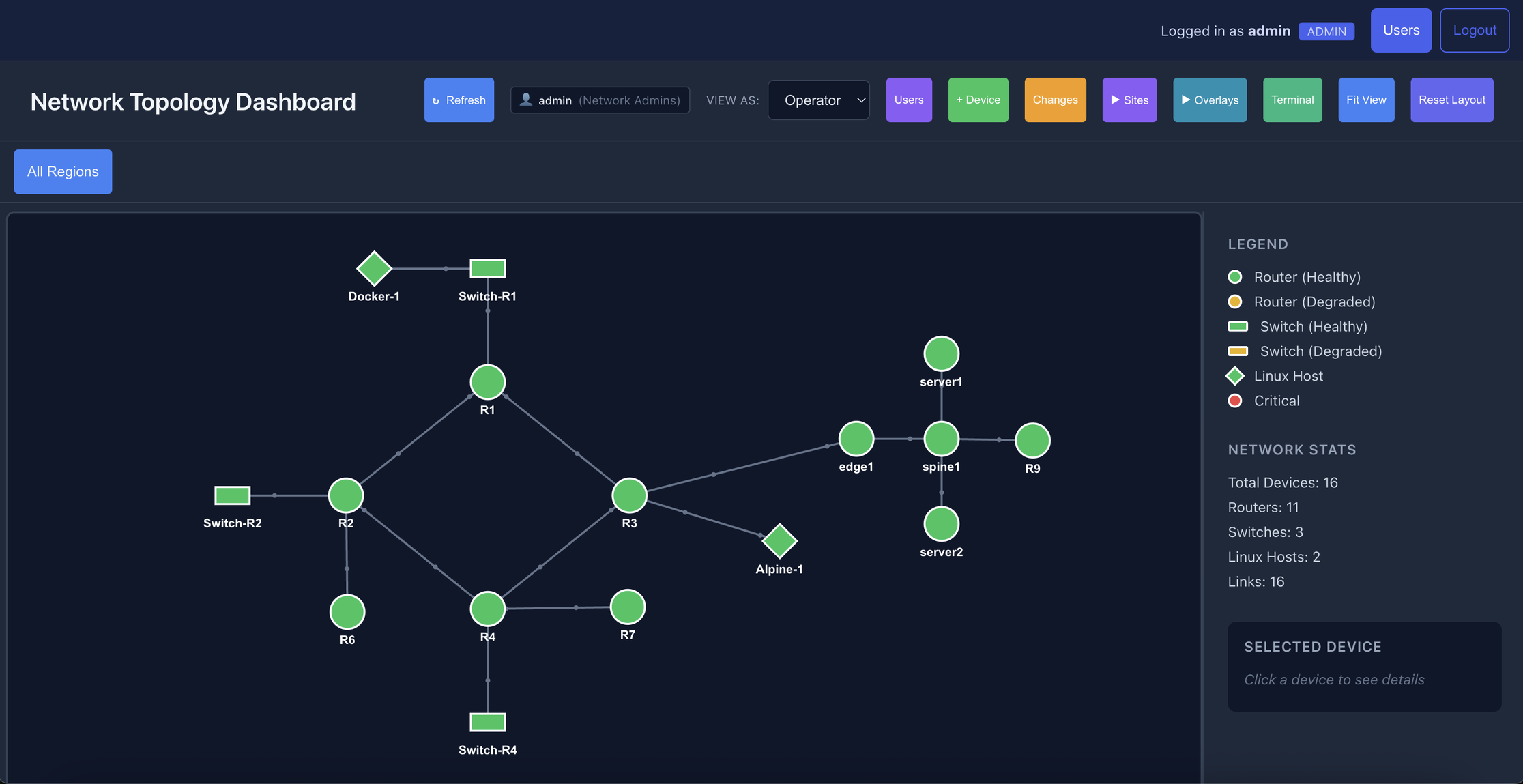
Before any change executes, the impact analyzer builds a dependency map. It parses live device state, including OSPF neighbor tables, BGP summaries, and routing tables, then identifies exactly what will break if you proceed. The analysis is protocol-aware. For a proposed interface shutdown, the system identifies OSPF adjacencies that will drop, BGP peers that become unreachable through subnet matching, routes that depend on that path, and whether alternate routes exist through different interfaces.
That last point is critical. A change that removes routes is LOW risk if every affected route has a backup path. The same change becomes HIGH risk the moment a single route has no failover. This works across platforms: Cisco IOS-XE, FRR in ContainerLab, and Nokia SR Linux.
Risk Categories, Not Scores
The system doesn't output a vague numeric score. It assigns a categorical risk level based on concrete conditions. NO_IMPACT means the interface is down or no adjacencies and routes are affected. LOW means routes were removed but all have alternate paths. MEDIUM means adjacencies were lost but all routes have alternates. HIGH means at least one route has no alternate path. CRITICAL means multiple adjacencies were lost on a single interface.
The distinction matters. You can act on "HIGH: 1 route has no alternate" in ways you can't act on "Risk Score: 73."
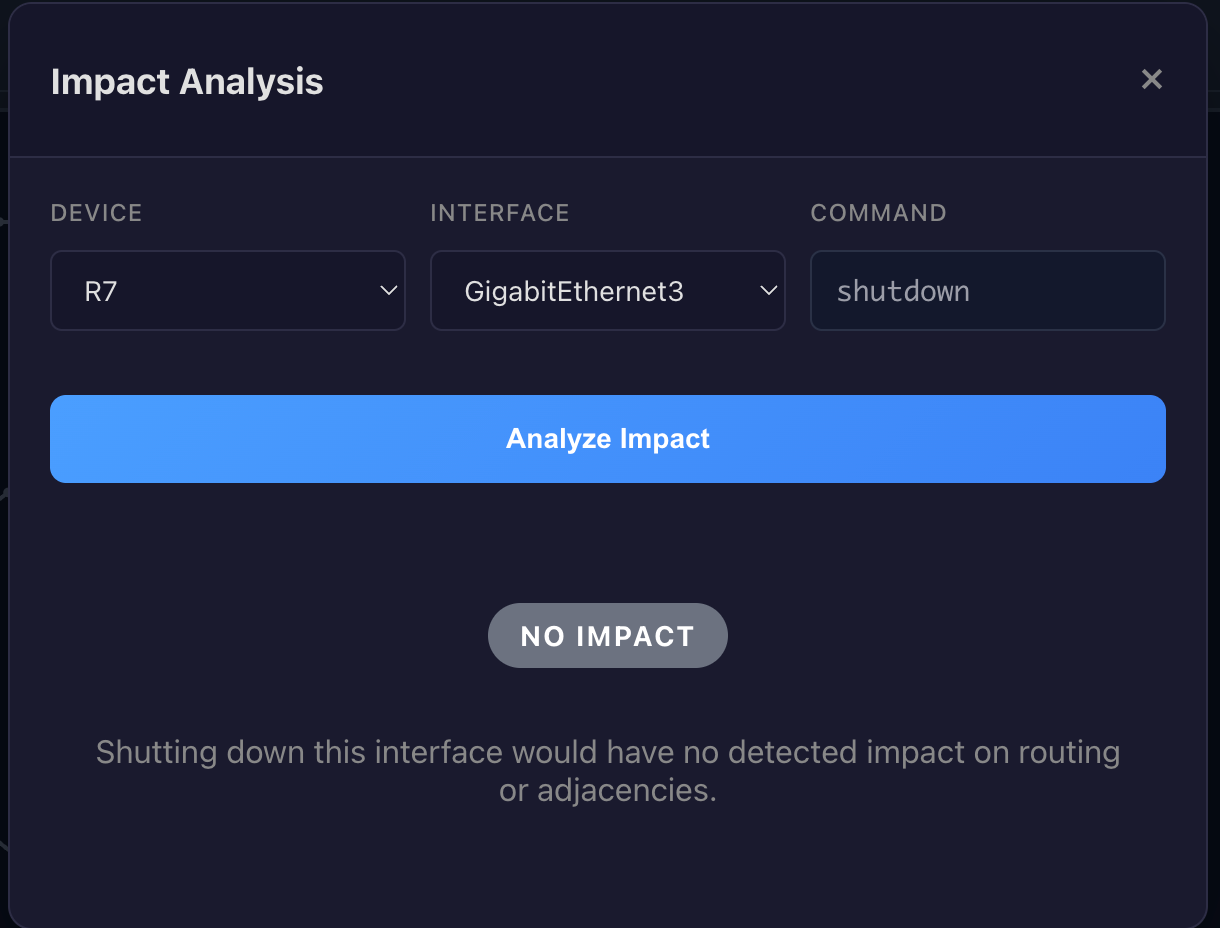
The Data Quality Gate
Here's something most automation ignores: the analyzer refuses to work with stale data. HIGH confidence means the data is less than 30 seconds old. MEDIUM confidence covers 30 to 120 seconds. LOW confidence spans 120 to 300 seconds. Beyond 5 minutes or if data is missing entirely, the system refuses to proceed. You can't make good decisions with bad information, and the system enforces this principle automatically.
Tracking State Over Time
Impact analysis tells you what will happen. But how do you know if something has happened? That's where the trending engine comes in.
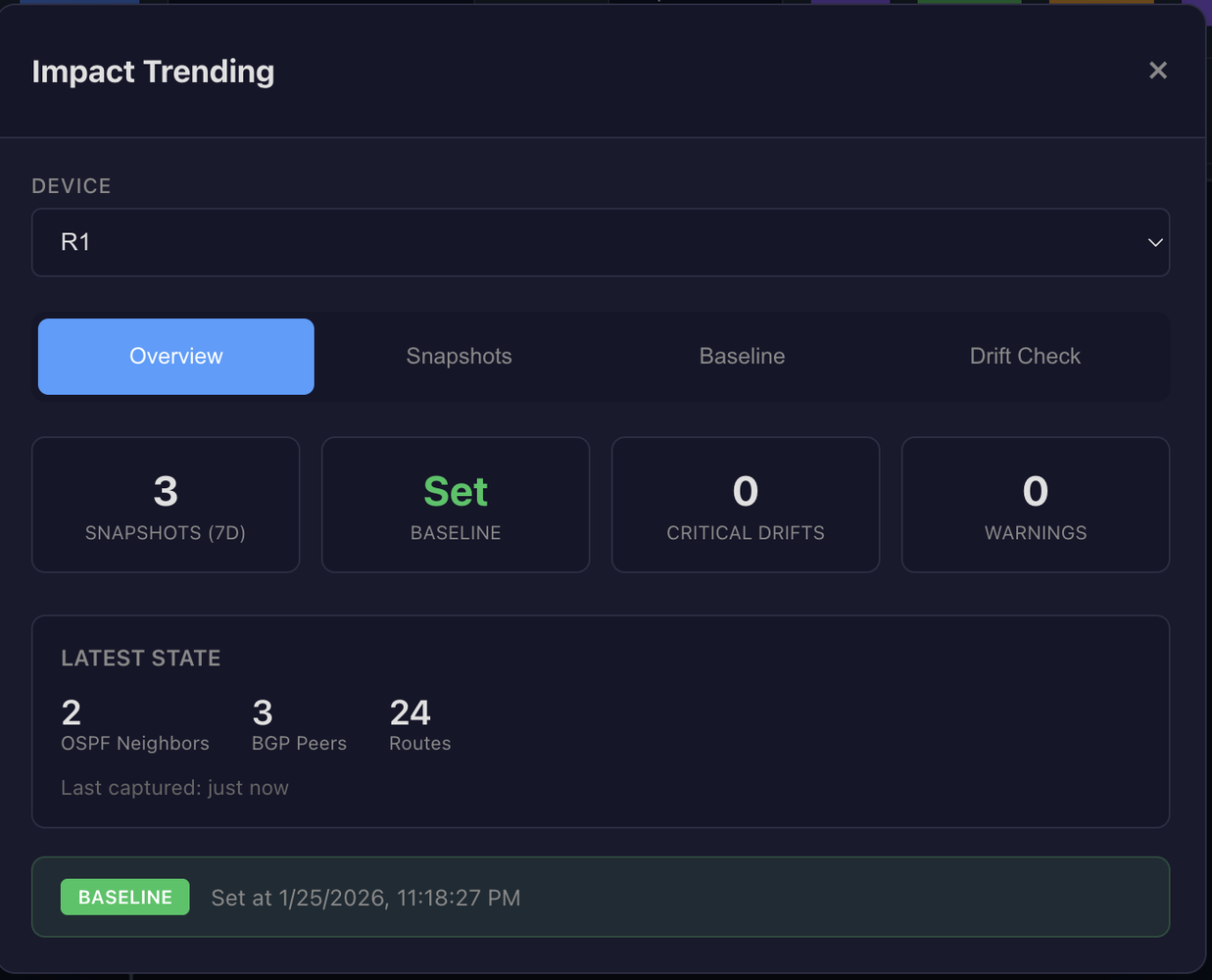
The system captures snapshots of operational state: OSPF neighbor tables, BGP peer status, route counts, interface states. These aren't configuration backups. They're point-in-time captures of how the network is actually behaving.
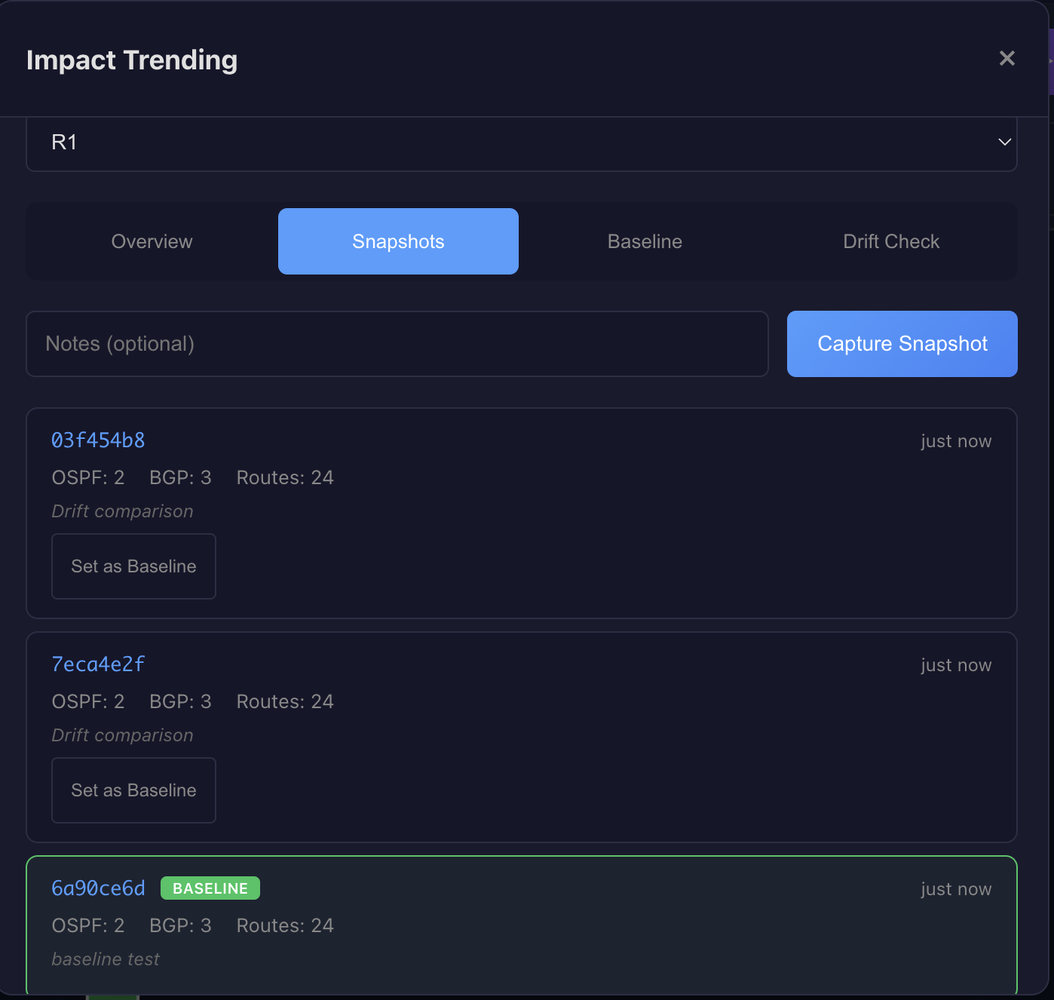
Baselines and Drift Detection
A baseline represents "known good" state. When you've verified a device is healthy, you save that snapshot as the baseline. Future drift detection compares current state against this reference.
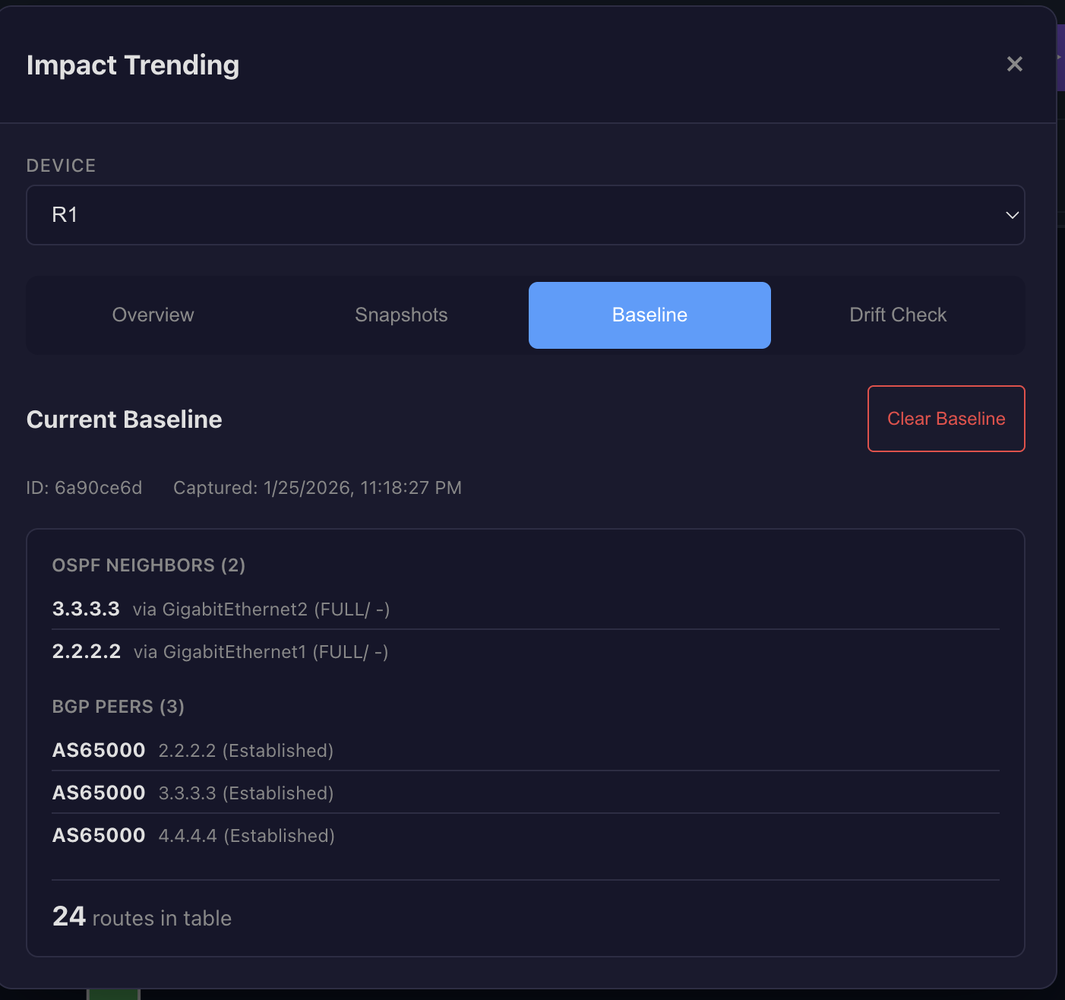
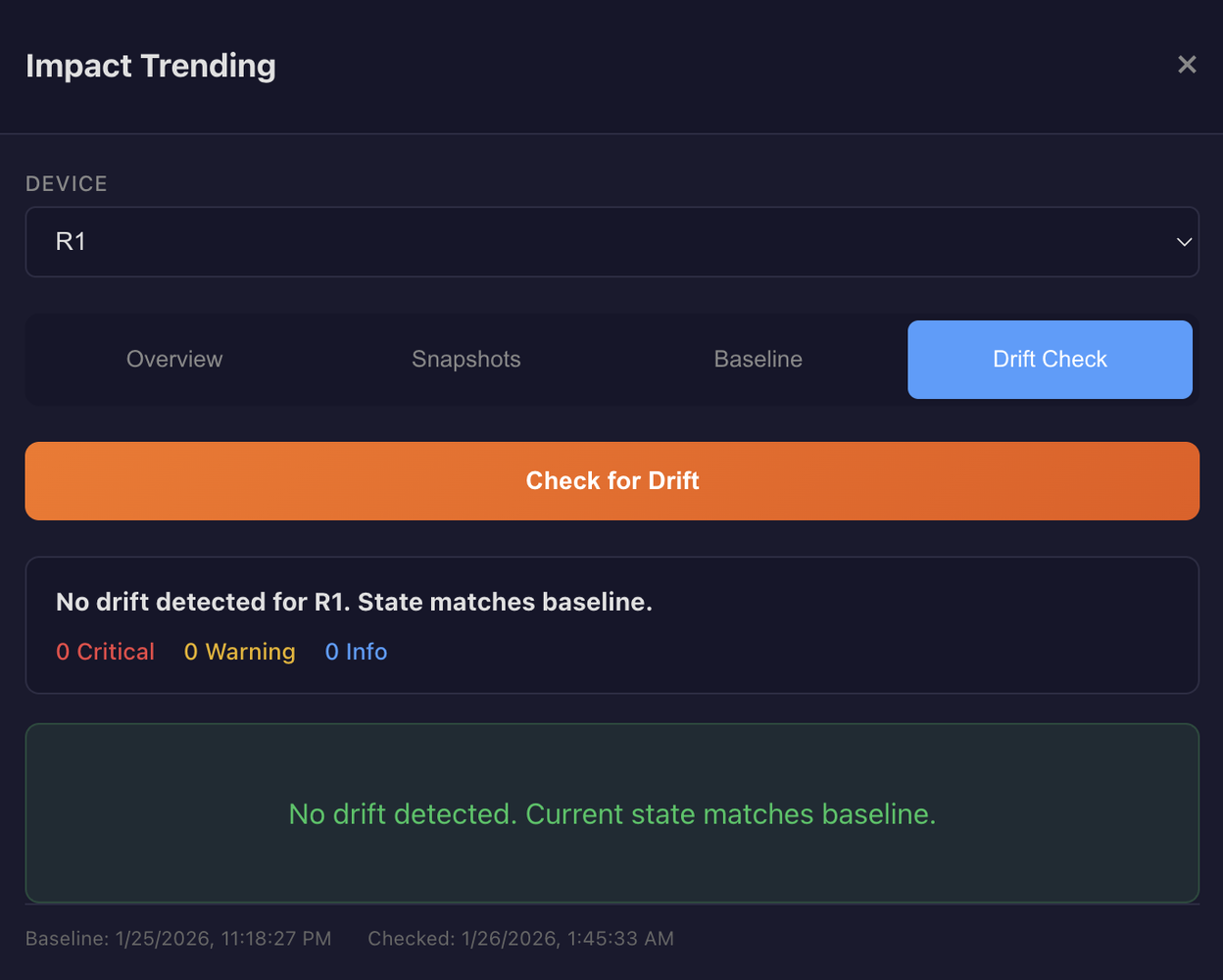
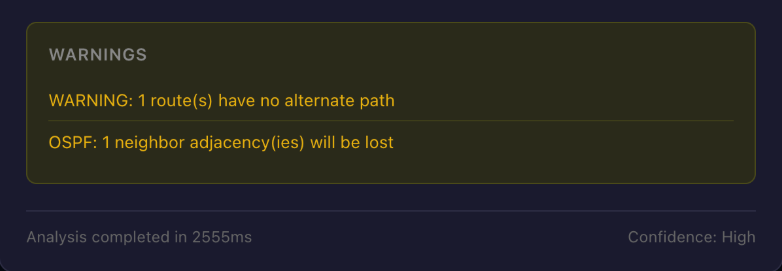
The system detects specific drift types including OSPF neighbors lost or added, BGP peers lost or added, interfaces going down or coming up, and route counts changing unexpectedly. Some drift is expected. That's the point of the change. But unexpected drift on devices outside your direct impact radius? That's your early warning system catching failures you wouldn't notice until morning.
The AI Layer
AI doesn't replace the operator. It formalizes intent. When I describe what I want in natural language, the system translates that into a dependency-aware change plan, surfaces risks I might miss, and waits for my approval. The integration works through Anthropic's Model Context Protocol. Claude can query device dependencies, check data freshness, and generate validated change proposals, but it never executes without human confirmation.
The AI layer doesn't make the system faster at executing changes. It makes the system faster at understanding consequences.
Real Example: The Interface Shutdown
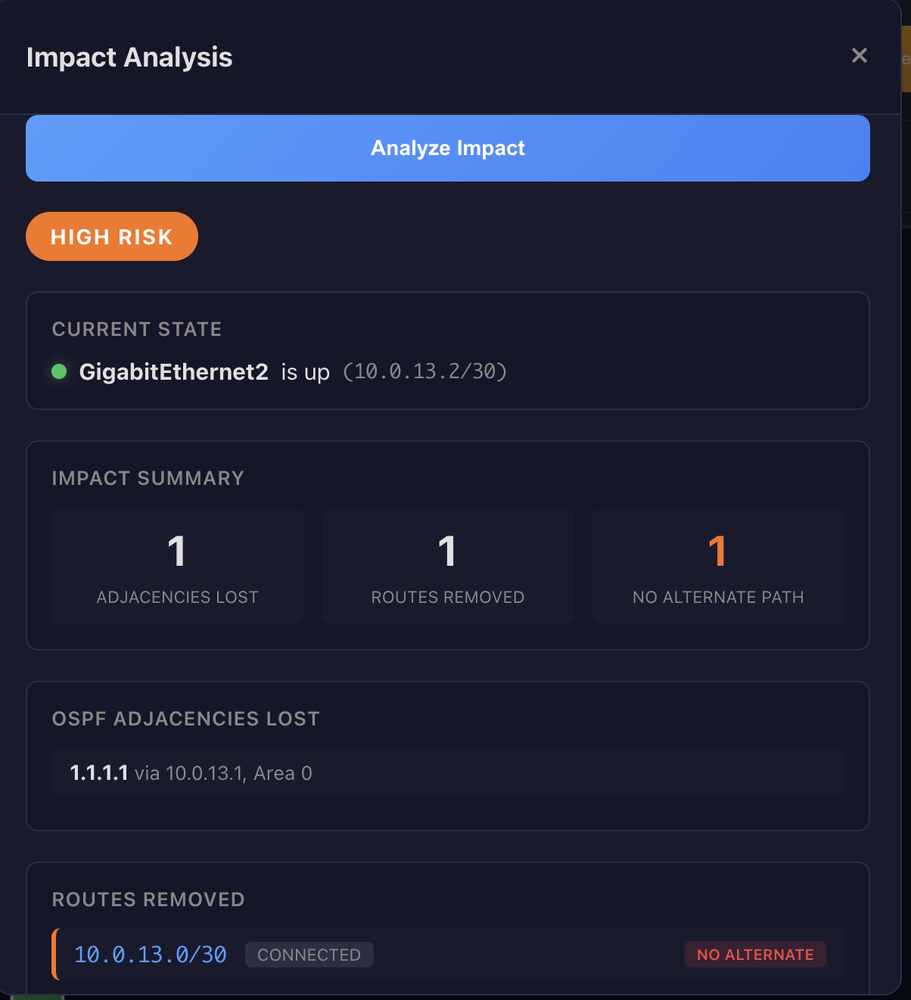
Last month I simulated decommissioning a link between two distribution switches. Simple task: shut down an interface on each side. The kind of change that takes thirty seconds manually.
When I ran impact analysis, the system returned HIGH risk. One route, a /30 connected network, had no alternate path. The OSPF adjacency would drop, and there was no redundant link for that subnet. The response included the exact warning: "1 route(s) have no alternate path." That's the kind of dependency that can be missed manually.
Results
After months of running this system across a 16-device multi-vendor lab, the change is less about metrics and more about mindset. I no longer hesitate before hitting Enter. When I propose a change, I know exactly what will break before I commit. When something unexpected happens, drift detection catches it in seconds rather than hours.
The fear doesn't go away. But it transforms from paralyzing uncertainty into healthy vigilance backed by automated verification. That's the difference between hoping a change will work and knowing whether it did.